Rでテキストマイニングを試してみる(2)ストップワードとワードクラウド

こんにちは。前回に続いて R でテキストマイニングを試してみることにします。
前回までの問題点
前回はとりあえず、Rで形態素解析をし、形態素ごとの頻度を数えてみました。

対象の文章は、前回と同じで梶井基次郎「檸檬」です。
単に形態素を数えたのでは、ほとんど意味を取ることができない「助詞」「助動詞」が出現回数の上位になってしまいました。
そこで、次に品詞を「名詞」「動詞」「形容詞」に絞って頻度を数えることにしました。
その結果を再掲します。
TERM POS1 POS2 lemon.txt
361 私 名詞 代名詞 72
85 の 名詞 非自立 46
54 する 動詞 自立 42
20 いる 動詞 非自立 40
43 こと 名詞 非自立 19
62 それ 名詞 代名詞 19
108 もの 名詞 非自立 19
118 よう 名詞 非自立 16
82 なる 動詞 自立 14
668 来る 動詞 非自立 14
153 一 名詞 数 12
210 街 名詞 一般 12
78 ない 形容詞 自立 11
104 みる 動詞 非自立 11
302 言う 動詞 自立 11
121 れる 動詞 接尾 10
601 美しい 形容詞 自立 10
46 さ 名詞 接尾 9
411 出る 動詞 自立 9
700 檸檬 名詞 一般 9
前回の結果を見ても、まだ不十分です。
例えば「の」「いる」「こと」「もの」「よう」・・・あたりも意味を取ることができません。
これらの共通点は、POS2 が「非自立」になっていることです。
さらに、「れる」「さ」という言葉も意味を取ることができません。
こちらの共通点は、POS2 が「接尾」となっていることです。
今回は、このような不要な言葉を除いていくことにします。
不要な品詞の下位区分を除いてみる
それでは、先ほど確認した品詞の下位区分にある「非自立」「接尾」を除いてみます。
そのプログラムです。
library(RMeCab)
lemon1<-docDF(file.choose(),type=1)
lemon2<-lemon1[lemon1$POS1 %in% c("名詞","動詞","形容詞") & !(lemon1$POS2 %in% c("非自立","接尾")),]
head(lemon2[order(lemon2$lemon.txt,decreasing = TRUE),],10)
それでは結果を見てみましょう。
TERM POS1 POS2 lemon.txt
509 私 名詞 代名詞 72
101 する 動詞 自立 42
117 それ 名詞 代名詞 19
176 なる 動詞 自立 14
293 一 名詞 数 12
352 街 名詞 一般 12
168 ない 形容詞 自立 11
446 言う 動詞 自立 11
761 美しい 形容詞 自立 10
562 出る 動詞 自立 9
かなり良くなってきたように思えます。
しかし、「する」「それ」といった語句もあまり意味を取ることができません。
次にこれらの語句を除くことにします。
ストップワードを設定する
もう品詞を頼りに除外していくのは難しそうです。
それで、個別の語句指定して除外していくことにします。
このような形態素解析で対象外とする語句をストップワードといいます。
ストップワードを設定して、梶井基次郎「檸檬」の形態素解析をしてみます。
そのプログラムです。
library(RMeCab)
stop_words<-c("する","それ","なる","ない","そこ","これ","ある")
lemon1<-docDF(file.choose(),type=1)
lemon2<-lemon1[lemon1$POS1 %in% c("名詞","動詞","形容詞") & !(lemon1$POS2 %in% c("非自立","接尾"))& !(lemon1$TERM %in% stop_words),]
head(lemon2[order(lemon2$lemon.txt,decreasing = TRUE),],10)
ストップワードとして「する」「それ」「なる」「ない」「そこ」「これ」「ある」を指定しました。
その実行結果です。
TERM POS1 POS2 lemon.txt
509 私 名詞 代名詞 72
293 一 名詞 数 12
352 街 名詞 一般 12
446 言う 動詞 自立 11
761 美しい 形容詞 自立 10
562 出る 動詞 自立 9
861 檸檬 名詞 一般 9
597 心 名詞 一般 8
726 二 名詞 数 8
332 果物 名詞 一般 7
棒グラフで表してみる
視覚的にとらえられるよう、棒グラフにしてみます。
library(RMeCab)
library(ggplot2)
stop_words<-c("する","それ","なる","ない","そこ","これ","ある")
lemon1<-docDF(file.choose(),type=1)
lemon2<-lemon1[lemon1$POS1 %in% c("名詞","動詞","形容詞") & !(lemon1$POS2 %in% c("非自立","接尾"))& !(lemon1$TERM %in% stop_words),]
lemon3<-lemon2[order(lemon2$lemon.txt,decreasing = TRUE),][1:25,]
ggplot(lemon3,aes(x=reorder(lemon3$TERM,lemon3$lemon.txt),y=lemon3$lemon.txt))+
geom_bar(stat="identity")+
theme_bw(base_size = 15)+
coord_flip()
出来上がった棒グラフです。
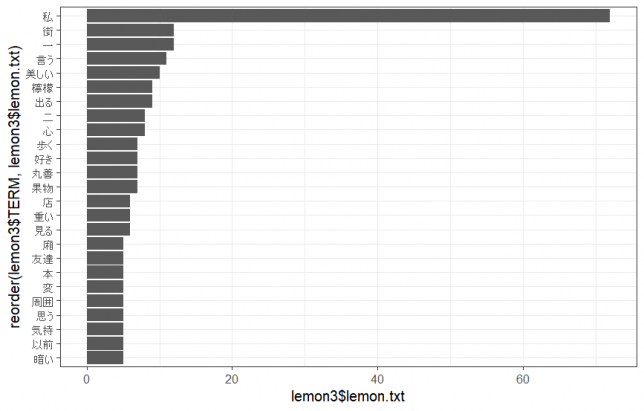
「私」がダントツです。続いて「街」「一」「言う」「美しい」「檸檬」となっています。
「丸善」という固有名詞も気になるところです。
ワードクラウドを描いてみる
ストップワードにより不要な語句を除いた結果を用いて、ワードクラウドを描いてみます。
wordcloud(lemon2$TERM,lemon2$lemon.txt,color=rainbow(7),scale=c(5,1),random.order = FALSE)
出来上がったワードクラウドです。

今回はこれでおしまいにします。それではまた。