超簡単な字句解析器を作ってみる

こんにちは。
前々回に逆ポーランド記法で書かれた数式を計算するプログラムを作りました。
しかし、小学校以来学んでいる記法とは異なるので、とても扱いにくいものです。
それならば、普通の計算式を入力して計算できるようにしよう!ということで、そのために超簡単な字句解析器を作ってみます。
受理する文字列を決める
はじめに受理する文字列を決めます。
計算なので、数値が必要そうです。小数も計算できるとよいので、ドットも使えるようにします。
とりあえず四則演算ができてほしいので、+-*/を扱えるようにします。
余りも計算できるとよいので、%も扱えるようにします。
多くの数式では括弧も使うので、(と)を扱えるようにします。
これらの組み合わせで数式ができるものとします。
これだけではぐちゃぐちゃなので、順に整理しながら受理する文字列を決めていきます。
空白を読み飛ばす
数式を見やすくするために、空白を入れても受理できるようにします。
状態遷移図は次になります。
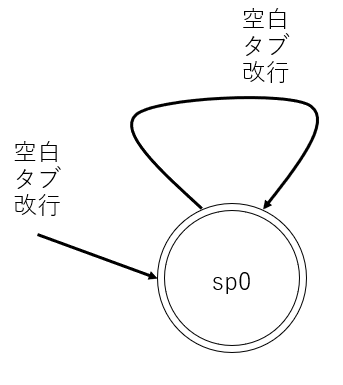
この部分のプログラムは次のようになります。
while (s[i] == ' ' || s[i]=='\t' || s[i]=='\n'){
i++;
}
数値として受理する文字列
次に数値を受理します。
マイナスと引き算がややこしいので、負の数はとりあえず止めておくことにします。
それなのに、小数は受理できるようにしようと思っています。
状態遷移図は次になります。
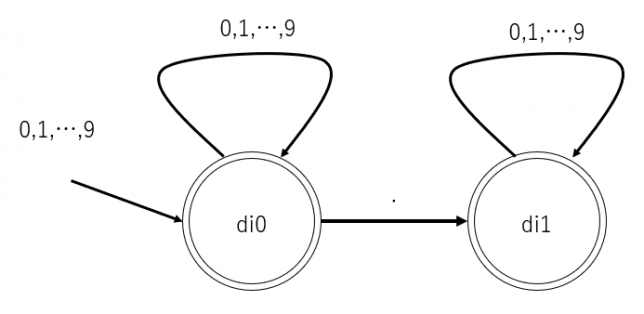
この状態遷移図で、整数と小数が受理できます。
手を抜いた結果として、「123.」というようなドットで終わる場合も受理できてしまいますが、気にしないことにします。
この部分のプログラムは次になります。
string res = "";
if('0'<=s[i] && s[i]<='9'){
res += s[i++];
while('0'<=s[i] && s[i]<='9'){
res += s[i++];
}
if(s[i]=='.'){
res += s[i++];
}
while('0'<=s[i] && s[i]<='9'){
res += s[i++];
}
i--;
_addToken(res, "digit");
continue;
}
演算子や括弧を受理する
次に演算子や括弧を受理できるようにします。
ここでは、たし算(+)と引き算(ー)の演算子を受理する状態遷移図を載せておきますが、他の演算子や括弧についても同様になります。
かけ算やわり算と分けたのは、計算の優先順位が異なるためです。
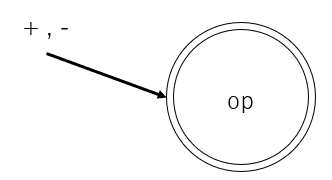
プログラムについては、まとめて載せます。
if(s[i]=='*' || s[i]=='/' || s[i]=='%'){
res = s[i];
_addToken(res, "operator1");
continue;
}
if(s[i]=='+' || s[i]=='-'){
res = s[i];
_addToken(res, "operator2");
continue;
}
if(s[i]=='(' ){
res = s[i];
_addToken(res, "leftPar");
continue;
}
if(s[i]==')' ){
res = s[i];
_addToken(res, "rightPar");
continue;
}
受理できなかった場合
ここまでで受理できなかった文字列は、想定したものではないため、例外を発生させて終了します。
throw runtime_error("Lexer error");
完成したプログラム
それでは、ここまでのプログラムをまとめて載せます。
ファイル名は lexer.h としておきます。
#include"MyLinkedList.h"
#include<string>
class lexer
{
public:
lexer(string s){
_tokenTypes = new MyLinkedList<string>;
_tokens = new MyLinkedList<string>;
for (int i = 0; i < s.length();i++){
while (s[i] == ' ' || s[i]=='\t' || s[i]=='\n'){
i++;
}
string res = "";
if('0'<=s[i] && s[i]<='9'){
res += s[i++];
while('0'<=s[i] && s[i]<='9'){
res += s[i++];
}
if(s[i]=='.'){
res += s[i++];
}
while('0'<=s[i] && s[i]<='9'){
res += s[i++];
}
i--;
_addToken(res, "digit");
continue;
}
if(s[i]=='*' || s[i]=='/' || s[i]=='%'){
res = s[i];
_addToken(res, "operator1");
continue;
}
if(s[i]=='+' || s[i]=='-'){
res = s[i];
_addToken(res, "operator2");
continue;
}
if(s[i]=='(' ){
res = s[i];
_addToken(res, "leftPar");
continue;
}
if(s[i]==')' ){
res = s[i];
_addToken(res, "rightPar");
continue;
}
throw runtime_error("Lexer error");
}
}
MyLinkedList<string> *getTokens(){
return _tokens;
}
MyLinkedList<string> *getTokenTypes(){
return _tokenTypes;
}
private:
MyLinkedList<string> *_tokenTypes;
MyLinkedList<string> *_tokens;
void _addToken(string token,string type){
_tokens->add(token);
_tokenTypes->add(type);
}
};
テスト用のプログラムで確かめてみます。
#include"lexer.h"
#include<string>
#include<iostream>
using namespace std;
int main(){
lexer* l = new lexer(" 3*( 45 / 70.3) % 2.+15.4");
cout << l->getTokens()->to_string() << endl;
cout << l->getTokenTypes()->to_string() << endl;
lexer* ll = new lexer("26.7.");
cout << ll->getTokens()->to_string() << endl;
cout << ll->getTokenTypes()->to_string() << endl;
}
実行結果です。
[3] → [*] → [(] → [45] → [/] → [70.3] → [)] → [%] → [2.] → [+] → [15.4]
[digit] → [operator1] → [leftPar] → [digit] → [operator1] → [digit] → [rightPar] → [operator1] → [digit] → [operator2] → [digit]
terminate called after throwing an instance of 'std::runtime_error'
what(): Lexer error
最初の数式は受理していますが、2つ目の数式では例外が発生しています。
あまりちゃんと書けていないような気がする・・・
今回はこれでおしまいにします。
それではまた。