特徴語を可視化しよう

こんにちは。前回までTF-IDFについて整理しました。単語(形態素)の数を数え、出現頻度を数えたり、複数の文章の中でどの程度出現するか数えたりということを行い、数値として値を求めていました。
しかし、数値でデータを見てすぐに軽重が判断できる人もいますが、必ずしもそのような人だけではありません。そこで、重要になるのはビジュアル化を行い、特徴をつかみやすくすることです。様々なビジュアル表現がありますが、ここではそのうちのいくつかを紹介したいと思います。
グラフで表現する
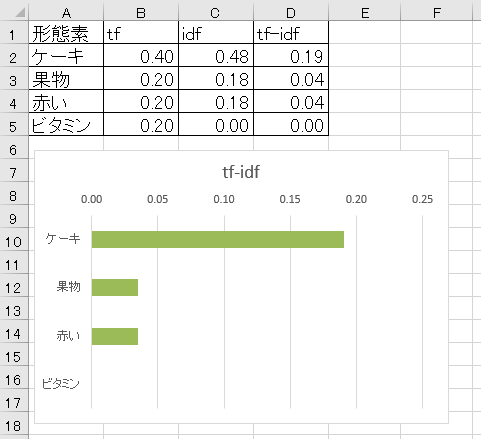
私たちは小学校以来さまざまなグラフでの表現を学習してきました。棒グラフ、折れ線グラフ、円グラフ、レーダーチャート、散布図などのことです。これまでTF-IDFで特徴語を求める際に、出現頻度の多少やTF-IDFの値の大小を用いて単語の重要性を検討してきました。そのような値の大小を用いることから、グラフの中でも適切なものは棒グラフになります。
TF-IDFの値を計算して棒グラフを描くのであれば、Pythonでプログラムを書き、その中でMatplotlibというようなモジュールを追加して自動的に描く方法もあります。しかし、私が授業で生徒に描かせるときにはその方法を採用しませんでした。採用した方法は、計算結果をExcelとして出力し、Excelで不要な単語の行を削除することをした後に、Excelのグラフ機能を用いて棒グラフを描かせました。
プログラム中でストップワードを指定すれば、不要な語を除いてグラフ化できます。しかし単に特徴語を抽出するだけでなく、他に機械学習による分類器を利用させたり、特徴語をもとに問題発見や問題解決を考えさせたり、分類器の活用方法を検討させたりすることも求めており、全グループにストップワードによる特徴語の取捨選択させるのは、負荷が重いと判断したためです。Excelであれば、データ行を削除をした瞬間にグラフからも消えてくれ、操作での負担を軽くできるのではないかと考えたためです。
その結果により作られたグラフは、次のようなものになります。
Word Cloudで表現する
次にWord Cloudによるビジュアル化について説明し、配布プログラムで描かせました。このプログラムでは、2種類の方法で不要語を除外していました。1つは品詞による選別を行いました。生徒に配布したプログラムでは、名詞・動詞・形容詞以外は除外するようにしていました。もう1つは、不要語をストップワード用のリストに値を持たせて引数として渡すことを行っていました。いずれもデフォルトを決めておきました。
この方法のよかった点は、プログラム中のストップワードなどが書かれた箇所を読めば、除外される対象がわかり、カスタマイズしたい生徒は手を加えることができる点です。今回はビジュアル化の話を中心に行うので、プログラムは次回以降の記事でまとめる予定を考えています。その際にご確認いただけるとよいかと思います。
出来上がった画像は、次のようなものになります。

授業ではPython のプログラムを配布して、Word Cloudを作成させました。
さらっと書きましたが、Word Cloudを作成するためのモジュールをインストールするのが案外大変です。インストール方法は、本記事では掲載しませんが、もしかしたら戸惑うかもしれません。pipコマンドで出たエラーを検索して、必要なものをインストールしました。記録していなかったので忘れてしまいましたが、.NET Frameworkだったかな…インストール方法を検索してたどり着いた人にはお詫びします。すみません。
Webサービスを利用する方法
お手軽に作成させるには、Webサイトを利用することもできます。特にUser Local テキストマイニングツールでは、Word Cloudを作ってくれるだけでなく、共起ワードをグラフ表示したり、特徴語をマッピングしてくれたりする機能もあり、多面的に文章の特徴を捉えることができます。



このようなサイトは便利だと思いますが、一度はどのような考えに基づいて分析されているかを知り、長所と短所を踏まえて分析した方が良いのではないかと思います。
今回は以上でおしまいです。次回は、授業で配布したプログラムを掲載する予定です。それでは、また。